Разработка и улучшение моделей машинного обучения для автоматического извлечения керна из изображений и поиска кварцевых жил
Евгений Барабошкин — руководитель по разработке продуктов DeepCore
Андрей Демидов — старший разработчик, Deep Learning-инженер
Денис Орлов — руководитель по развитию компании Digital Petroleum
Дмитрий Коротеев — генеральный директор
Введение
За многие годы работы в различных накопленных массивах данных о строении недр. Например, накопленный массив данных за период с 2008 по 2017 гг. только о государственных морских ВГР согласно отчету Росгеолфонда составляет 1571,75 Тб. Чтобы упростить обращение, создается множество алгоритмов для автоматического анализа и сочетания данных. Такие алгоритмы включают в себя анализ карт геохимических и геофизических аномалий, определения типов руд и магматических обстановок на основе точечных замеров, подсчитывают совокупный состав в 3D-объеме и множестве других исследований, функций помогают в поиске полезных ископаемых и собираемых работ исследований.
Многие из этих исследований основаны на применении методов машинного обучения, которые выбираются на основе набора данных в автоматическом счетчике их классификации или расчетной оценки тотального или иного параметра в зависимости от задачи. Как следует из названия — в ходе работы с данными алгоритм может «обучиться» выполнять ту или иную таблицу. Сам процесс «обучения» может быть проведен как на данных с оригинальным ответом (с учителем), так и без него (без учителя). Обучение алгоритму начинается с выдачи алгоритма, по своей сути, случайных ответов и в процессе обучения, оценивая себя по назначению метрикам, алгоритму, если данные позволяют, начинает выдавать всё больше правильных ответов или собирает данные в определённых группах. Оценка эффективности алгоритма может производиться с использованием текстур в зависимости от задачи.
Андрей Демидов — старший разработчик, Deep Learning-инженер
Денис Орлов — руководитель по развитию компании Digital Petroleum
Дмитрий Коротеев — генеральный директор
Введение
За многие годы работы в различных накопленных массивах данных о строении недр. Например, накопленный массив данных за период с 2008 по 2017 гг. только о государственных морских ВГР согласно отчету Росгеолфонда составляет 1571,75 Тб. Чтобы упростить обращение, создается множество алгоритмов для автоматического анализа и сочетания данных. Такие алгоритмы включают в себя анализ карт геохимических и геофизических аномалий, определения типов руд и магматических обстановок на основе точечных замеров, подсчитывают совокупный состав в 3D-объеме и множестве других исследований, функций помогают в поиске полезных ископаемых и собираемых работ исследований.
Многие из этих исследований основаны на применении методов машинного обучения, которые выбираются на основе набора данных в автоматическом счетчике их классификации или расчетной оценки тотального или иного параметра в зависимости от задачи. Как следует из названия — в ходе работы с данными алгоритм может «обучиться» выполнять ту или иную таблицу. Сам процесс «обучения» может быть проведен как на данных с оригинальным ответом (с учителем), так и без него (без учителя). Обучение алгоритму начинается с выдачи алгоритма, по своей сути, случайных ответов и в процессе обучения, оценивая себя по назначению метрикам, алгоритму, если данные позволяют, начинает выдавать всё больше правильных ответов или собирает данные в определённых группах. Оценка эффективности алгоритма может производиться с использованием текстур в зависимости от задачи.

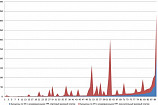
Рис. 1. Сравнение результатов предсказаний на новых данных, не похожих на изначальную выборку (А), и схожих данных (Б) при стандартном методе обучения методов машинного обучения для сегментации горных пород
Среди прочих работ ведутся активные исследования в области анализа изображений керна. В основном они нацелены на определение различных пород и текстур на основе тех или иных данных. При этом известны работы по определению как терригенных [1–3], так и магматических пород [4–6] и их текстур, и структур и других характеристик, например, RQD (Rock Quality Designation) [7].
При подготовке любого алгоритма машинного обучения необходимо учитывать применимость того или иного алгоритма, а также количество доступных данных.
В ходе подготовки моделей для нефтегазовой и рудной отрасли путём экспериментов авторами было установлено минимально необходимое количество изображений для верного определения характеристик на новом керне с того же месторождения. Так, например, в рамках одного месторождения может быть необходимо определить тип породы, наличие текстур, структур, включений. Для достижения точности 70 % требуется порядка 10 м керна на класс определяемой характеристики. При высокой скорости классификации (от долей секунд до нескольких секунд на метр керна, в зависимости от количества подключаемых процессоров и используемой архитектуры алгоритма) — такое качество, как правило, считается приемлемым для значительного облегчения работы эксперта на этапе внедрения системы при ограниченном наборе доступных данных, в дальнейшем качество улучшается за счёт дообучения на новых, размеченных в процессе использования системы, данных.
С точки зрения готовых для применения продуктов, в которых в той или иной степени реализовано применение машинного обучения для автоматического описания пород, существует несколько решений: DeepCore (RU), Coremetr (RU), Imago (US), Datarock (AU).
В одном из тестов системы DeepCore были разработаны различные модели для классификации сухого керна: поиск кварцевых жил и прожилков, поиск рудных компонент (включая арсенопирит), описание состояния керна (для подсчета RQD), описание литологии. Модели были опробованы на новых данных и показали свою эффективность.
В статье приведены результаты исследований, нацеленные на улучшение моделей машинного обучения, необходимых для работы ПО DeepCore. В данном ПО модели машинного обучения применяются на двух этапах: автоматический поиск керна с увязкой по глубине и классификация изображений керна. Задача автоматического поиска керна решается путём попиксельной классификации изображения — сегментации, задача классификации решается путём разделения выделенных столбиков керна на небольшие интервалы заданного масштаба (например 5 или 10 см) и дальнейшим предсказанием каждого такого интервала с выведением вероятности предсказания в пользовательский интерфейс.
Проблемы, их решение и результаты
Авторами проводятся постоянные исследования границ применения разработанных алгоритмов машинного обучения на новых данных для решения аналогичных задач, к которым эти алгоритмы были разработаны. При этом используются разнообразные новые данные из различных источников, которые ранее не представлялись алгоритмам. На данный момент накоплено больше 170 Гб данных. В ходе таких испытаний выявляются проблемы алгоритмов машинного обучения. Находя те или иные недостатки возможно разными способами их устранять.
Одна из выявленных проблем касается сегментации керна. Она возникает из-за недостаточной вариативности обучающих данных. При обучении алгоритмов стандартными методами на ограниченных выборках алгоритмы могут не справляться с работой на новых данных.
Так, например, если обучать модель на одном типе данных и применить на другом — результат может быть непредсказуем (рис. 1А). При этом, применяя модель на схожих данных — результат будет ожидаем (рис. 1Б).
Для увеличения вариативности данных на этапе обучения авторами был разработан новый подход, который состоит в создании новых изображений (аугментации) на основе существующих данных [8]. Так, например, из одного изображения ящика керна и нескольких отдельных столбцов керна можно создать несколько комбинаций (рис. 2). В ходе проведенного опроса не все респонденты (из 42 человек) смогли определить настоящее изображение.
После применения такого типа генераций изображений — результаты сегментации улучшились. Одним из параметров оценки алгоритма сегментации является метрика IOU (Intersection Over Union — степень пересечения между собой областей, выделенных экспертом и алгоритмом).

Рис. 2. Сгенерированные изображения с помощью разработанного алгоритма аугментации изображений (слева) и результаты опроса в социальных сетях (справа). В представленных изображениях — 4-е является исходным. Как видно из результатов опроса — респонденты не всегда могут ответить однозначно
После дополнительной генерации данных обучающей выборки метрика IOU на новых данных изменилась с 0,76 до 0,93 (рис. 3). Как видно на изображении — это позволило не только улучшить качество определения областей с керном на новых, ранее неизвестных изображениях (рис. 3A), но и уточнить выделение областей на схожих изображениях (рис. 3Б)

Рис. 3. Сравнение результатов предсказаний на новых данных, не похожих на изначальную выборку (А), и схожих данных (Б) с применением нового подхода к обучению методов машинного обучения для сегментации горных пород
При применении разработанного алгоритма внутри системы DeepCore — облегчается работа эксперта не только с какими-либо типовыми фотографиями керна, которые могут быть получены в пределах одного месторождения, но и различными другими изображениями, которые эксперт может получить в ходе разведки новых площадей или работы с архивными материалами. Как ранее было установлено [8] — применение автоматизированного извлечения керна способно облегчить работу специалиста и ускорить его работу в 20 раз. Применение алгоритма в связке с автоматической увязкой керна позволяет также упростить по лучение отдельных столбцов керна и уточнить их увязку за счет внесения изменений в привязку керна непосредственно на изображении (рис. 4), также возможно настроить алгоритмы на считывание информации о привязке непосредственно с изображения.
Следующим этапом работы с керновым материалом является описание керна. Ранее, среди прочих моделей для описания керна была разработана модель для поиска кварцевых жил и прожилков (кварц, кварцевые прожилки, порода). В собранных открытых данных был найден керн, в котором присутствовал кварц и кварцевые прожилки, что позволило провести новый эксперимент для ответа на вопрос — насколько точен будет алгоритм без и с дообучением на новых данных.

Рис. 4. Применение алгоритма в системе DeepCore с автоматической увязкой по глубине. Пользователь может изменить как произведенную маску, так и глубины, ориентируясь на дополнительную информацию о привязке
Тестирование проводилось на скважине общей протяженностью 98,48 м. В первичную обучающую выборку вх одило 2618 изображений размером 10x10 см, в новую выборку (без генерации изображений) — 14198 фотографий размером 10x10 см. Сравнивались две модели, первая модель была обучена на небольшой выборке, вторая же модель была дополнительно обучена на новой выборке. Скважина была предварительно размечена алгоритмом посредством DeepCore, далее эк сперт правил результаты разметки. В конце произведено сравнение по сантиметрам результатов разметки моделей и экспертной правки (рис. 5).
По результатам сравнения были составлены матрицы неточностей (рис. 6) и посчитаны различные метрики качества при сравнении описаний сантиметр к сантиметру. Так, первая модель, обученная на минимальном количестве данных, достигла микро-то чности классификации в 76 %, при этом после дообучения — микро-точность классификации составила 91 %. Как видно из матрицы неточностей (рис. 6) — некоторые интервалы были переинтерпретированы. Первая модель (рис. 6А) не относила изображения кварца к породе (5 см), в то время как вторая модель определила часть кварца как породу (22 см). Каждый такой случай уникальный и должен рассматриваться отдельно, т.к. из-за сравнения данных сантиметр-к-сантиметру в некоторых случаях эксперт мог немного сдвинуть границу определений в смежных областях керн/порода. Общая протяженность изменённых интервалов 9,15 м, медианная длина — 10 см, средняя — 11 см, минимальная — 2 см, максимальная — 40 см. Медианная длина изменений говорит о том, что эксперт в основном изменял некоторые определения 10x10 см целиком. Время, необходимое для классификации 98 м пород алгоритмом в масштабе 1:10 — 10 мин. (на описание 100 м керна у человека обычно уходит от 6 часов до нескольких дней). Ранее было установлено, что в среднем после внедрения алгоритмов в производственный процесс на начальном этапе — они позволяют ускорить работу в 7 раз [9, 10].

Рис. 5. Различные версии интерпретации новых данных: А — первая модель, без дообучения; Б — новая модель, после дообучения; В — разметка экспертом. Точность второй модели значительно выше благодаря дообучению на дополнительных данных
Результаты описания могут быть быстро проанализированы для поиска перспективных интервалов (например, наибольшее содержание кварца на метр керна, рис. 7). В разрезе могут быть выделены наиболее перспективные области содержания того или иного компонента и прослежены другие зависимости. Применяя несколько моделей для определения типа пород, кварца, пирита, возможно за короткий срок получить зависимость и распределения различных параметров, а, следовательно, и распределение сопутствующих рудных компонент (редкоземельных металлов, золота и проч.). Особенно это актуально когда необходимо быстро проанализировать большое количество скважин. Как видно из графиков (рис. 7), различие между экспертным и предсказанным значением незначительно. Таким образом, возможно в экспресс режиме обработать несколько сотен скважин и отправить данные на предварительную оценку. Далее эксперт может проверить все результаты, внести исправление и уточнить результаты оценки. Благодаря тому, что алгоритмы могут быть дообучены — после внесения изменений в результат работы алгоритмов и дообучения на этих данных — количество изменений, вносимых эк спертом в результаты, постепенно сокращается, что в дальнейшем значительно упрощает работу эксперта.

Рис. 6. Сравнение раезультатов предсказания разных моделей с экспертным значением в матрицах неточностей (по диагонали — верно определенные интервалы). А — первая модель, без дообучения, Б — новая модель, после дообучения
Выводы
В результате проведенных экспериментов по применению и дообучению моделей сегментации и классификации были выявлены ограничения по их применению на новых данных, полностью отличных от тех, что использовались при обучении моделей.
Показаны пути решения этих проблем и результаты, которые могут быть получены после улучшения алгоритмов с помощью разных методов (увеличение выборки, применение новых методов аугментации).

Рис. 7. Сравнение результатов классификации новым алгоритмом (синяя линия) и экспертом (зелёная линия) при проведении валового анализа содержания той или иной компоненты в метровом интервале, а также диаграммы, показывающие процентное соотношение
Благодаря применению алгоритмов искусственного интеллекта и компьютерного зрения значительно облегчается работа эксперта и уточняются данные описания, что в конечном счете влияет на качество конечной модели и позволяет уточнить запасы.
Ранее было установлено, что применение новых подходов автоинтерпретации изображений на первоначальных этапах внедрения даёт значительный эффект и ускоряет работу специалиста в 7 раз. По мере развития и улучшения алгоритмов постепенно возрастает и эффект от их применения. Как показано — после доработки алгоритмов точность определений доходит до 90 %.
Разработанная платформа DeepCore позволяет в кратчайшие сроки дообучать специализированные интерпретационные модели в зависимости от решаемых задач конкретного пользователя. Платформа активно внедряется в отрасли и используется крупными нефтегазовыми и золотодобывающими компаниями.
 1. Baraboshkin E.E. et al. Deep convolutions for in-depth automated rock typing // Comput Geosci. 2020. Vol. 135.
1. Baraboshkin E.E. et al. Deep convolutions for in-depth automated rock typing // Comput Geosci. 2020. Vol. 135.
2. Fan G. et al. Recognizing Multiple Types of Rocks Quickly and Accurately Based on Lightweight CNNs Model // IEEE Access. 2020. Vol. 8.
3. Zhang Y., Mingchao L., Shuai H. Automatic identification and classification in lithology based on deep learning in rock images // Acta Petrologica Sinica. 2018. Vol. 34.
4. Xu Z. et al. Integrated lithology identification based on images and elemental data from rocks // J Pet Sci Eng. Elsevier, 2021. Vol. 205.
5. Liu X. et al. Research on intelligent identification of rock types based on faster R-CNN method // IEEE Access. Institute of Electrical and Electronics Engineers Inc., 2020. Vol. 8.
6. Fuid D. et al. Deep learning based lithology classification of drill core images // PLoS One / ed. P.P. Abdul Majeed A. Public Library of Science, 2022. Vol. 17, № 7.
7. Alzubaidi F. et al. Automated Rock Quality Designation Using Convolutional Neural Networks // Rock Mechanics and Rock Engineering 2022. Springer, 2022. Vol. 1. P. 1–16.
8. Baraboshkin E.E. et al.Распознавание изображений керновых ящиков и его усовершенствование с помощью новой техники дополнений // Comput Geosci. 2022. Том. 162.
9. Барабошкин Е.Е. и соавт. Применение автоматизированного полнопроходного описания керна для производственных целей. От идеи к ИТ-продукту // Наука о данных в нефти и газе 2021. Европейская ассоциация геологов и инженеров, 2021. С. 1–6.
10. Барабошкин Э.Е. и соавт. Применение автоматизированной системы полнопроходного описания керна в производстве. Пример использования // Пути реализации нефтегазового потенциала Западной Сибири. Ханты-Мансийск, 2022. С. 293–299.
Опубликовано в журнале «Золото и технологии», № 3 (57)/сентябрь 2022 г.